Full stack developer
The backend is organized around an agent harness that runs a two-stage data workflow. Discovery pipelines find and queue monastery/community sources, and enrichment pipelines transform those raw findings into structured, comparable records. The system treats agent runs as backend jobs, with shared schemas and validation between pipeline stages so downstream and frontend pages consume clean, consistent data. This design separates crawling/collection from normalization/scoring, which makes the platform easier to scale, debug, and iterate as new sources are added.
What I Worked On
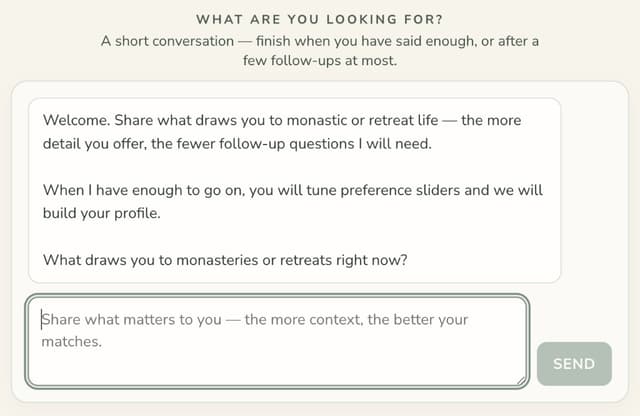
Discovery chat
The discovery chat is a short, turn-limited conversation powered by a Next.js API route that calls OpenAI with a custom system prompt. The model extracts qualitative context (narrative summary, readiness intent, and any user-volunteered constraints) while deliberately avoiding numeric scoring.

Profile scoring / scales
User preferences are captured as 0–100 bipolar spectrum sliders (spiritual orientation, community structure, lifestyle) plus a 1–5 seriousness scale, normalized to a fixed [0, 1] vector and mapped onto community feature dimensions through rules that handle semantic pole inversions. Community-side scores are LLM-extracted jsonb (grouped by practice, community, lifestyle, etc.) normalized to the same vector space; matching applies hard filters on region and tradition, then ranks candidates with a weighted mean absolute distance across aligned dimensions.
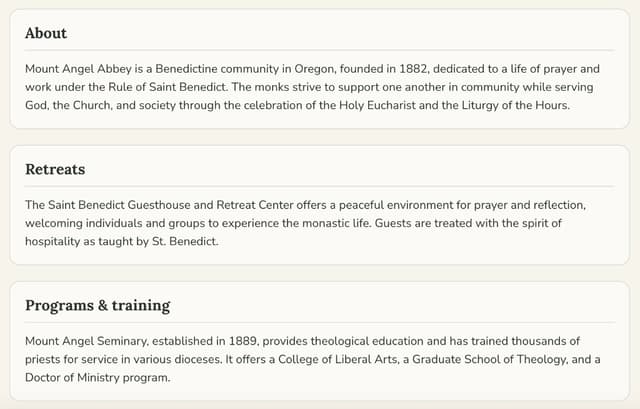
Community information
Community information is gathered through the harness's agentic discovery-to-enrichment flow: discovery agents identify relevant monastery/community sources, then enrichment agents extract and normalize fields like About, Retreats, location, and practices into a shared schema. Instead of one-off scraping logic, the backend uses reusable agent steps, validation gates, and structured outputs so new communities can be added with the same pipeline and quality checks.
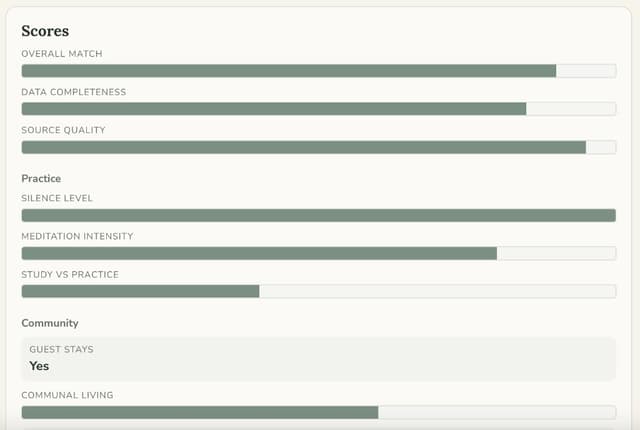
Community scoring
Scoring is also agent-driven: enrichment agents produce normalized feature values, then a deterministic scoring stage maps those values onto shared scales and calculates composite community scores. This keeps the "agentic" part focused on evidence collection/interpretation while the final scale math stays consistent, transparent, and easy to recalibrate over time.
Technologies